Chapter 6 Clusters
I have a very large army and very large dragons.
— Daenerys Targaryen
Previous chapters focused on using Spark over a single computing instance, your personal computer. In this chapter, we introduce techniques to run Spark over multiple computing instances, also known as a computing cluster. This chapter and subsequent ones will introduce and make use of concepts applicable to computing clusters; however, it’s not required to use a computing cluster to follow along, so you can still use your personal computer. It’s worth mentioning that while previous chapters focused on single computing instances, you can also use all the data analysis and modeling techniques we presented in a computing cluster without changing any code.
If you already have a Spark cluster in your organization, you could consider skipping to Chapter 7, which teaches you how to connect to an existing cluster. Otherwise, if you don’t have a cluster or are considering improvements to your existing infrastructure, this chapter introduces the cluster trends, managers, and providers available today.
6.1 Overview
There are three major trends in cluster computing worth discussing: on-premises, cloud computing, and Kubernetes. Framing these trends over time will help us understand how they came to be, what they are, and what their future might be. To illustrate this, Figure 6.1 plots these trends over time using data from Google trends.
For on-premises clusters, you or someone in your organization purchased physical computers that were intended to be used for cluster computing. The computers in this cluster are made of off-the-shelf hardware, meaning that someone placed an order to purchase computers usually found on store shelves, or high-performance hardware, meaning that a computing vendor provided highly customized computing hardware, which also comes optimized for high-performance network connectivity, power consumption, and so on.

FIGURE 6.1: Google trends for on-premises (mainframe), cloud computing, and Kubernetes
When purchasing hundreds or thousands of computing instances, it doesn’t make sense to keep them in the usual computing case that we are all familiar with; instead, it makes sense to stack them as efficiently as possible on top of one another to minimize the space the use. This group of efficiently stacked computing instances is known as a rack. After a cluster grows to thousands of computers, you will also need to host hundreds of racks of computing devices; at this scale, you would also need significant physical space to host those racks.
A building that provides racks of computing instances is usually known as a datacenter. At the scale of a datacenter, you would also need to find ways to make the building more efficient, especially the cooling system, power supplies, network connectivity, and so on. Since this is time-consuming, a few organizations have come together to open source their infrastructure under the Open Compute Project initiative, which provides a set of datacenter blueprints free for anyone to use.
There is nothing preventing you from building our own datacenter, and, in fact, many organizations have followed this path. For instance, Amazon started as an online bookstore, but over the years it grew to sell much more than just books. Along with its online store growth, its datacenters also grew in size. In 2002, Amazon considered renting servers in their datacenters to the public, and two years later, Amazon Web Services (AWS) launched as a way to let anyone rent servers in the company’s datacenters on demand, meaning that you did not need to purchase, configure, maintain, or tear down your own clusters; rather, you could rent them directly from AWS.
This on-demand compute model is what we know today as cloud computing. In the cloud, the cluster you use is not owned by you, and it’s not in your physical building; instead it’s a datacenter owned and managed by someone else. Today, there are many cloud providers in this space, including AWS, Databricks, Google, Microsoft, Qubole, and many others. Most cloud computing platforms provide a user interface through either a web application or command line to request and manage resources.
While the benefits of processing data in the cloud were obvious for many years, picking a cloud provider had the unintended side effect of locking in organizations with one particular provider, making it hard to switch between providers or back to on-premises clusters. Kubernetes, announced by Google in 2014, is an open source system for managing containerized applications across multiple hosts. In practice, it makes it easier to deploy across multiple cloud providers and on-premises as well.
In summary, we have seen a transition from on-premises to cloud computing and, more recently, Kubernetes. These technologies are often loosely described as the private cloud, the public cloud, and as one of the orchestration services that can enable a hybrid cloud, respectively. This chapter walks you through each cluster computing trend in the context of Spark and R.
6.2 On-Premise
As mentioned in the overview section, on-premises clusters represent a set of computing instances procured and managed by staff members from your organization. These clusters can be highly customized and controlled; however, they can also incur higher initial expenses and maintenance costs.
When using on-premises Spark clusters, there are two concepts you should consider:
- Cluster manager
- In a similar way as to how an operating system (like Windows or macOS) allows you to run multiple applications in the same computer, a cluster manager allows multiple applications to be run in the same cluster. You need to choose one yourself when working with on-premises clusters.
- Spark distribution
- While you can install Spark from the Apache Spark site, many organizations partner with companies that can provide support and enhancements to Apache Spark, which we often refer to as Spark distributions.
6.2.1 Managers
To run Spark within a computing cluster, you will need to run software capable of initializing Spark over each physical machine and register all the available computing nodes. This software is known as a cluster manager. The available cluster managers in Spark are Spark Standalone, YARN, Mesos, and Kubernetes.
Note: In distributed systems and clusters literature, we often refer to each physical machine as a compute instance, compute node, instance, or node.
6.2.1.1 Standalone
In Spark Standalone, Spark uses itself as its own cluster manager, which allows you to use Spark without installing additional software in your cluster. This can be useful if you are planning to use your cluster to run only Spark applications; if this cluster is not dedicated to Spark, a generic cluster manager like YARN, Mesos, or Kubernetes would be more suitable. The Spark Standalone documentation contains detailed information on configuring, launching, monitoring, and enabling high availability, as illustrated in Figure 6.2.
However, since Spark Standalone is contained within a Spark installation, by completing Chapter 2, you have now a Spark installation available that you can use to initialize a local Spark Standalone cluster on your own machine. In practice, you would want to start the worker nodes on different machines, but for simplicity, we present the code to start a standalone cluster on a single machine.
First, retrieve the SPARK_HOME directory by running spark_home_dir(), and then start the master node and a worker node as follows:
# Retrieve the Spark installation directory
spark_home <- spark_home_dir()
# Build paths and classes
spark_path <- file.path(spark_home, "bin", "spark-class")
# Start cluster manager master node
system2(spark_path, "org.apache.spark.deploy.master.Master", wait = FALSE)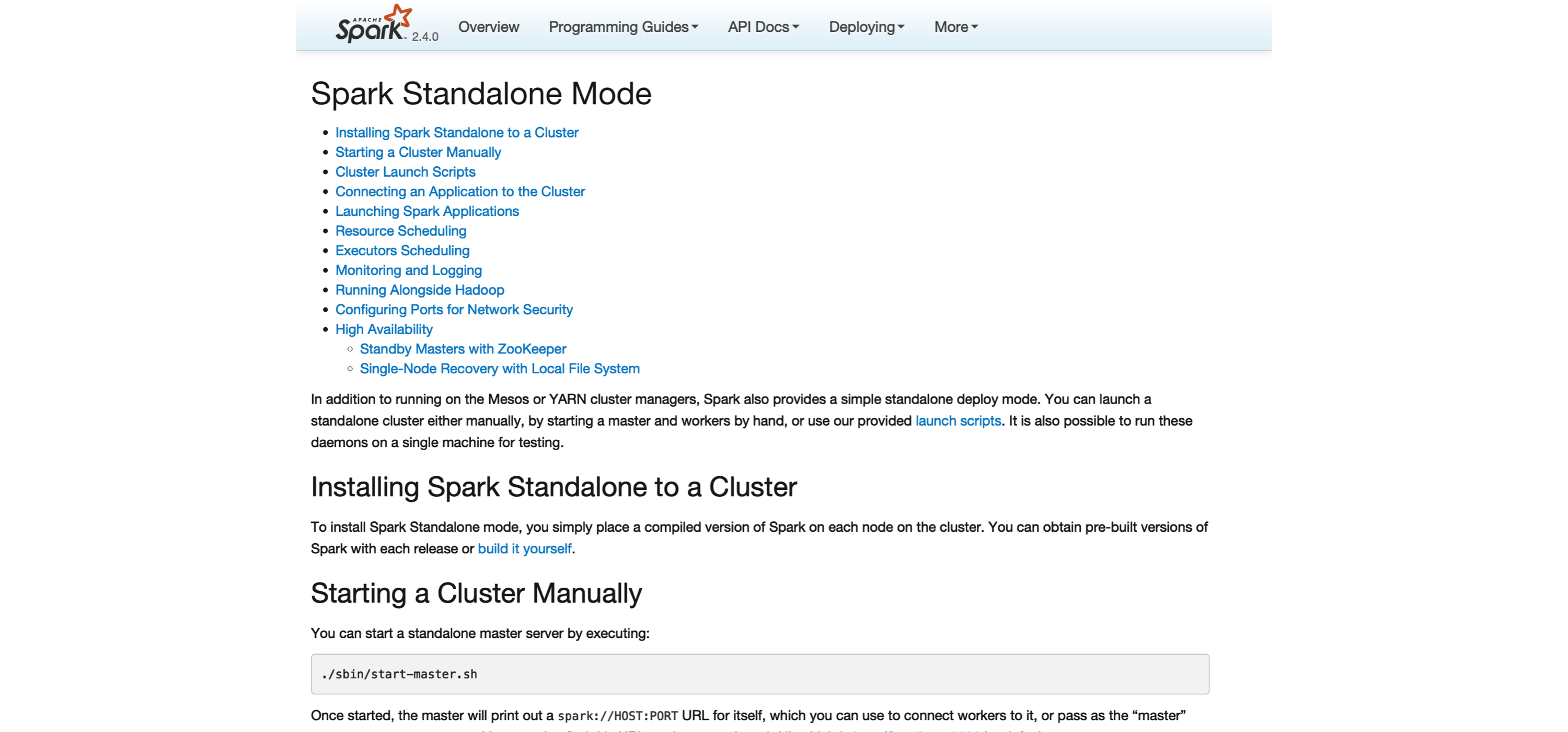
FIGURE 6.2: Spark Standalone website
The previous command initializes the master node. You can access the master node interface at localhost:8080, as captured in Figure 6.3. Note that the Spark master URL is specified as spark://address:port; you will need this URL to initialize worker nodes.
We then can initialize a single worker using the master URL; however, you could use a similar approach to initialize multiple workers by running the code multiple times and, potentially, across different machines:
# Start worker node, find master URL at http://localhost:8080/
system2(spark_path, c("org.apache.spark.deploy.worker.Worker",
"spark://address:port"), wait = FALSE)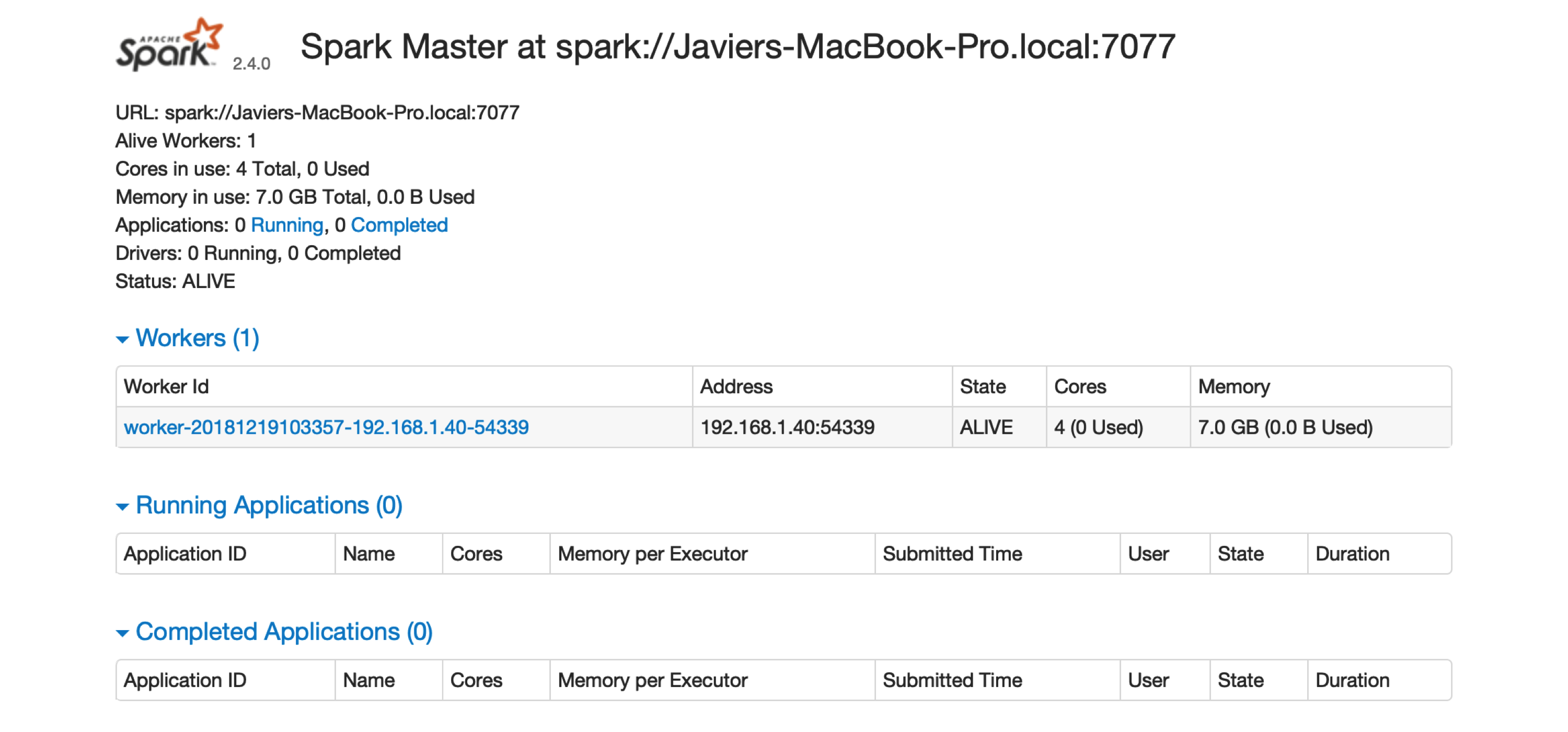
FIGURE 6.3: The Spark Standalone web interface
There is one worker register in Spark Standalone. Click the link to this worker node to view details for this particular worker, like available memory and cores, as shown in Figure 6.4.
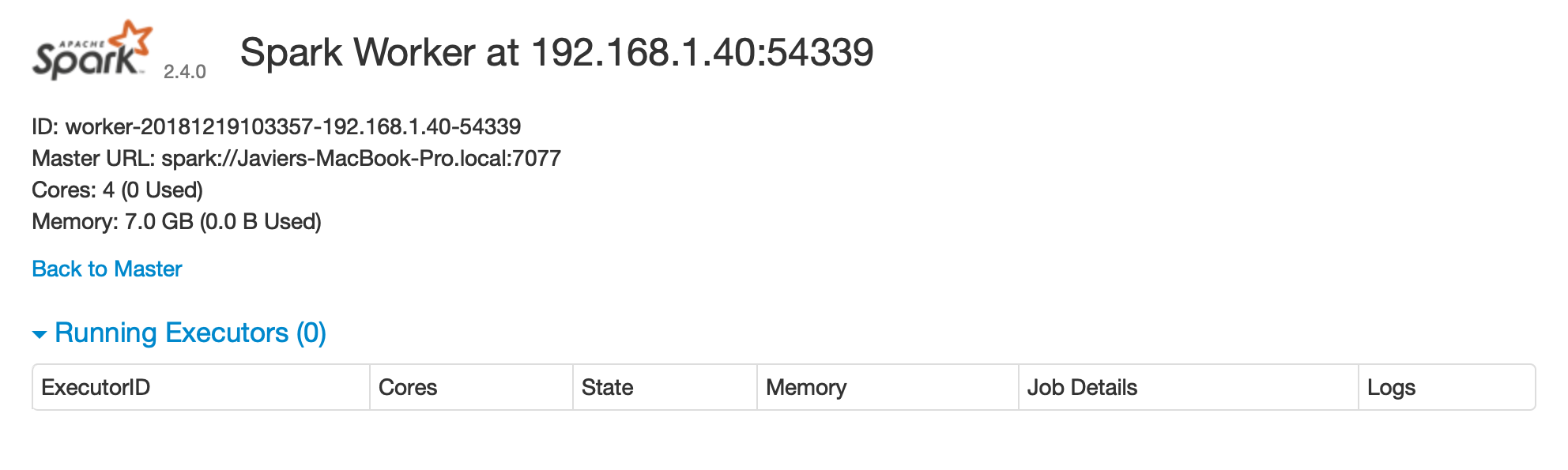
FIGURE 6.4: Spark Standalone worker web interface
After you are done performing computations in this cluster, you will need to stop the master and worker nodes. You can use the jps command to identify the process numbers to terminate. In the following example, 15330 and 15353 are the processes that you can terminate to finalize this cluster. To terminate a process, you can use system("Taskkill /PID ##### /F") in Windows, or system("kill -9 #####") in macOS and Linux.
15330 Master
15365 Jps
15353 Worker
1689 QuorumPeerMainYou can follow a similar approach to configure a cluster by running the initialization code over each machine in the cluster.
While it’s possible to initialize a simple standalone cluster, configuring a proper Spark Standalone cluster that can recover from computer restarts and failures, and supports multiple users, permissions, and so on, is usually a much longer process that falls beyond the scope of this book. The following sections present several alternatives that can be much easier to manage on-premises or through cloud services. We will start by introducing YARN.
6.2.1.2 Yarn
Hadoop YARN, or simply YARN, as it is commonly called, is the resource manager of the Hadoop project. It was originally developed in the Hadoop project but was refactored into its own project in Hadoop 2. As we mentioned in Chapter 1, Spark was built to speed up computation over Hadoop, and therefore it’s very common to find Spark installed on Hadoop clusters.
One advantage of YARN is that it is likely to be already installed in many existing clusters that support Hadoop; this means that you can easily use Spark with many existing Hadoop clusters without requesting any major changes to the existing cluster infrastructure. It is also very common to find Spark deployed in YARN clusters since many started out as Hadoop clusters and were eventually upgraded to also support Spark.
You can submit YARN applications in two modes: yarn-client and yarn-cluster. In yarn-cluster mode the driver is running remotely (potentially), while in yarn-client mode, the driver is running locally. Both modes are supported, and we explain them further in Chapter 7.
YARN provides a resource management user interface useful to access logs, monitor available resources, terminate applications, and more. After you connect to Spark from R, you will be able to manage the running application in YARN, as shown in Figure 6.5.
Since YARN is the cluster manager from the Hadoop project, you can find YARN’s documentation at hadoop.apache.org. You can also reference the “Running Spark on YARN” guide at spark.apache.org.
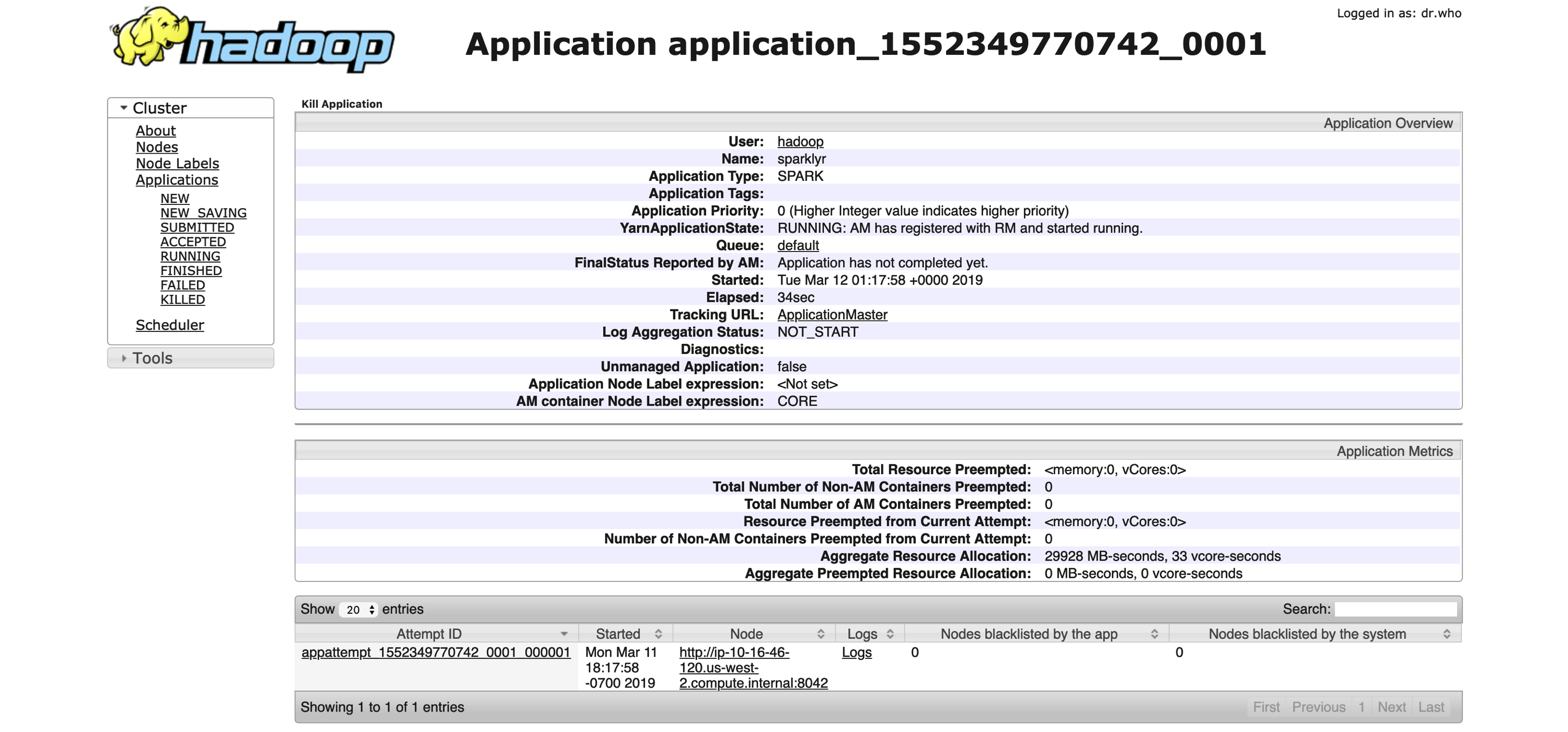
FIGURE 6.5: YARN’s Resource Manager running a sparklyr application
6.2.1.3 Mesos
Apache Mesos is an open source project to manage computer clusters. Mesos began as a research project in the UC Berkeley RAD Lab. It makes use of Linux Cgroups to provide isolation for CPU, memory, I/O, and file system access.
Mesos, like YARN, supports executing many cluster frameworks, including Spark. However, one advantage particular to Mesos is that it allows cluster frameworks like Spark to implement custom task schedulers. A scheduler is the component that coordinates in a cluster which applications are allocated execution time and which resources are assigned to them. Spark uses a coarse-grained scheduler, which schedules resources for the duration of the application; however, other frameworks might use Mesos’ fine-grained scheduler, which can increase the overall efficiency in the cluster by scheduling tasks in shorter intervals, allowing them to share resources between them.
Mesos provides a web interface to manage your running applications, resources, and so on. After connecting to Spark from R, your application will be registered like any other application running in Mesos. Figure 6.6 shows a successful connection to Spark from R.
Mesos is an Apache project with its documentation available at mesos.apache.org. The Running Spark on Mesos guide is also a great resource if you choose to use Mesos as your cluster manager.
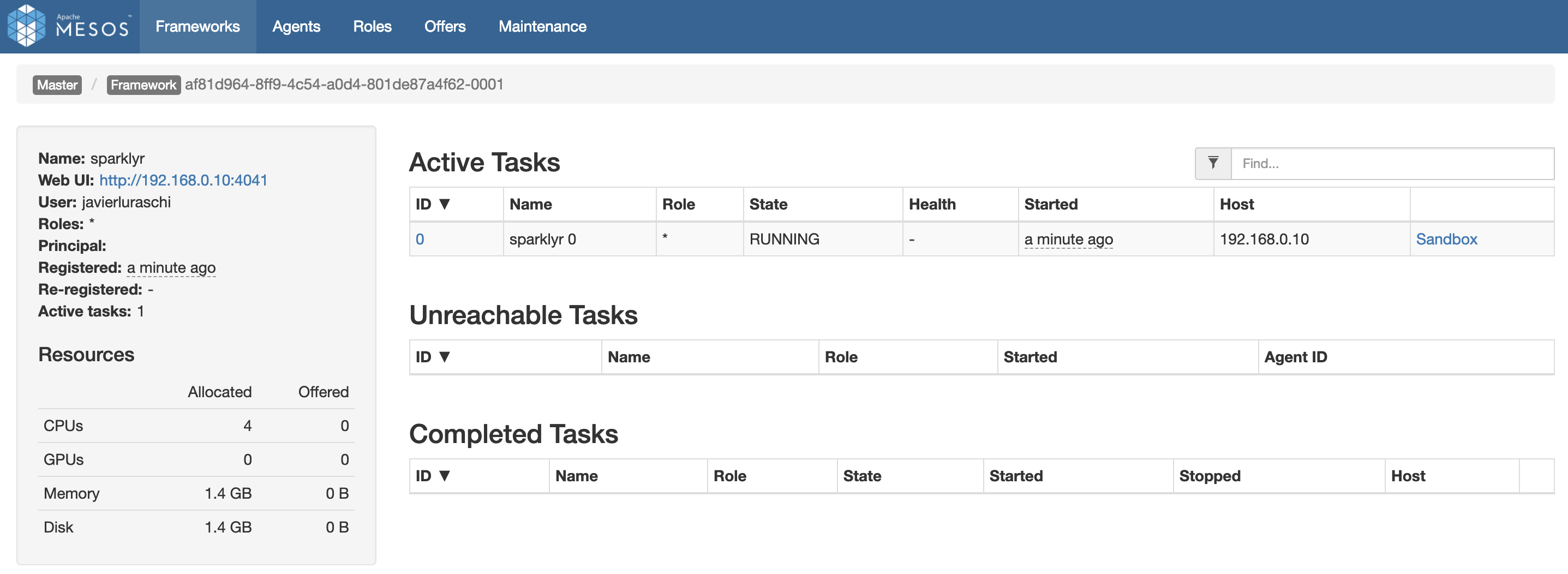
FIGURE 6.6: Mesos web interface running Spark and R
6.2.2 Distributions
You can use a cluster manager in on-premises clusters, as described in the previous section; however, many organizations—including, but not limited to, Apache Spark—choose to partner with companies providing additional management software, services, and resources to help manage applications in their cluster. Some of the on-premises cluster providers include Cloudera, Hortonworks, and MapR, which we briefly introduce next.
Cloudera, Inc., is a US-based software company that provides Apache Hadoop and Apache Spark–based software, support and services, and training to business customers. Cloudera’s hybrid open source Apache Hadoop distribution, Cloudera Distribution Including Apache Hadoop (CDH), targets enterprise-class deployments of that technology. Cloudera donates more than 50% of its engineering output to the various Apache-licensed open source projects (Apache Hive, Apache Avro, Apache HBase, and so on) that combine to form the Apache Hadoop platform. Cloudera is also a sponsor of the Apache Software Foundation.
Cloudera clusters make use of parcels, which are binary distributions containing program files and metadata. Spark happens to be installed as a parcel in Cloudera. It’s beyond the scope of this book to present how to configure Cloudera clusters, but resources and documentation can be found under cloudera.com, and “Introducing sparklyr, an R Interface for Apache Spark” on the Cloudera blog.
Cloudera provides the Cloudera Manager web interface to manage resources, services, parcels, diagnostics, and more. Figure 6.7 shows a Spark parcel running in Cloudera Manager, which you can later use to connect from R.
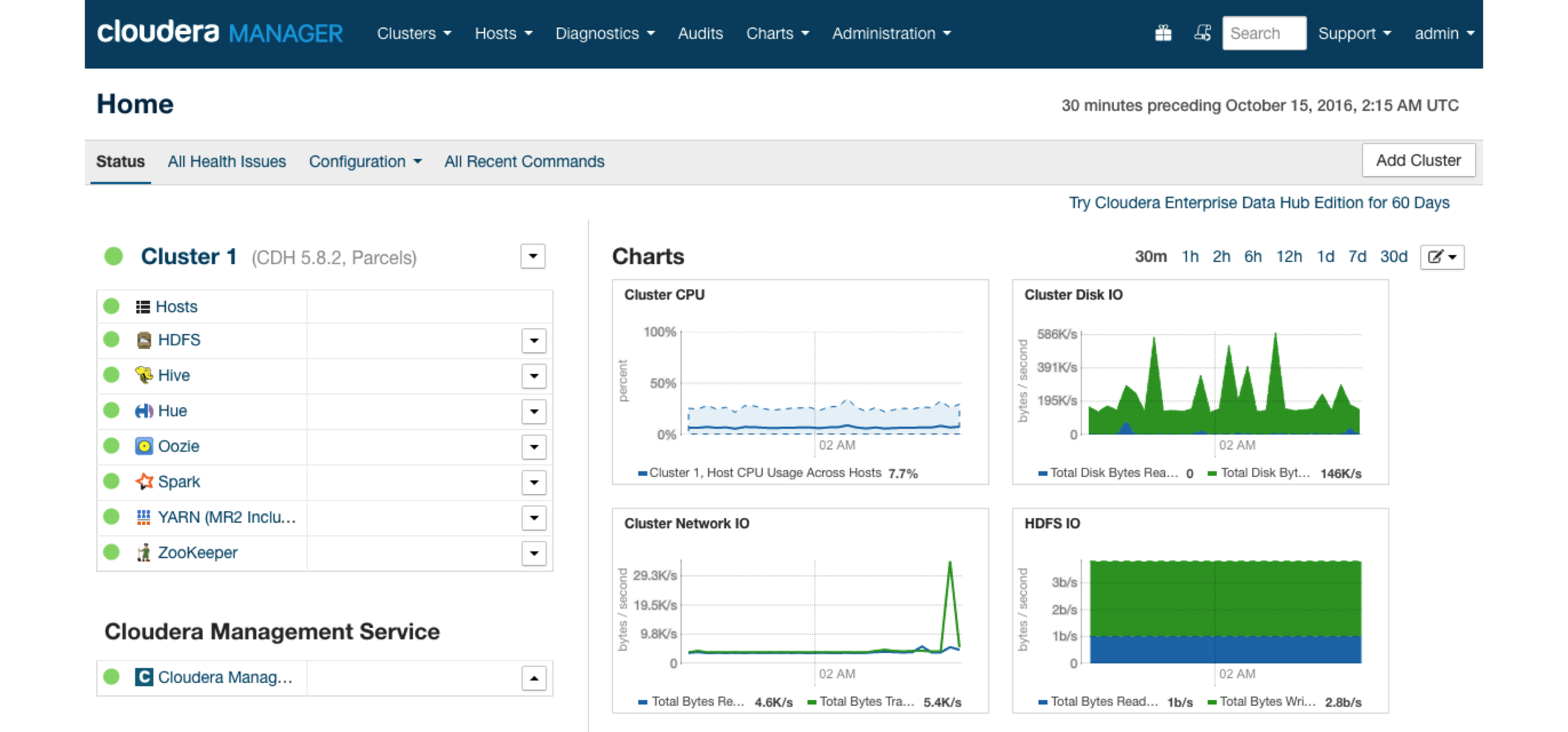
FIGURE 6.7: Cloudera Manager running Spark parcel
sparklyr is certified with Cloudera, meaning that Cloudera’s support is aware of sparklyr and can be effective helping organizations that are using Spark and R. Table 6.1 summarizes the versions currently certified.
| Cloudera.Version | Product | Version | Components | Kerberos |
|---|---|---|---|---|
| CDH5.9 | sparklyr | 0.5 | HDFS, Spark | Yes |
| CDH5.9 | sparklyr | 0.6 | HDFS, Spark | Yes |
| CDH5.9 | sparklyr | 0.7 | HDFS, Spark | Yes |
Hortonworks is a big data software company based in Santa Clara, California. The company develops, supports, and provides expertise on an expansive set of entirely open source software designed to manage data and processing for everything from Internet of Things (IoT) to advanced analytics and machine learning. Hortonworks believes that it is a data management company bridging the cloud and the datacenter.
Hortonworks partnered with Microsoft to improve support in Microsoft Windows for Hadoop and Spark, which used to be a differentiation point from Cloudera; however, comparing Hortonworks and Cloudera is less relevant today since the companies merged in January 2019. Despite the merger, support for the Cloudera and Hortonworks Spark distributions are still available. Additional resources to configure Spark under Hortonworks are available at hortonworks.com.
MapR is a business software company headquartered in Santa Clara, California. MapR provides access to a variety of data sources from a single computer cluster, including big data workloads such as Apache Hadoop and Apache Spark, a distributed file system, a multimodel database management system, and event stream processing, combining analytics in real time with operational applications. Its technology runs on both commodity hardware and public cloud computing services.
6.3 Cloud
If you have neither an on-premises cluster nor spare machines to reuse, starting with a cloud cluster can be quite convenient since it will allow you to access a proper cluster in a matter of minutes. This section briefly mentions some of the major cloud infrastructure providers and gives you resources to help you get started if you choose to use a cloud provider.
In cloud services, the compute instances are billed for as long the Spark cluster runs; your billing starts when the cluster launches, and it stops when the cluster stops. This cost needs to be multiplied by the number of instances reserved for your cluster. So, for instance, if a cloud provider charges $1.00 per compute instance per hour, and you start a three-node cluster that you use for one hour and 10 minutes, it is likely that you’ll receive a bill for $1.00 x 2 hours x 3 nodes = $6.00. Some cloud providers charge per minute, but at least you can rely on all of them charging per compute hour.
Be aware that, while computing costs can be quite low for small clusters, accidentally leaving a cluster running can cause significant billing expenses. Therefore, it’s worth taking the extra time to check twice that your cluster is terminated when you no longer need it. It’s also a good practice to monitor costs daily while using clusters to make sure your expectations match the daily bill.
From past experience, you should also plan to request compute resources in advance while dealing with large-scale projects; various cloud providers will not allow you to start a cluster with hundreds of machines before requesting them explicitly through a support request. While this can be cumbersome, it’s also a way to help you control costs in your organization.
Since the cluster size is flexible, it is a good practice to start with small clusters and scale compute resources as needed. Even if you know in advance that a cluster of significant size will be required, starting small provides an opportunity to troubleshoot issues at a lower cost since it’s unlikely that your data analysis will run at scale flawlessly on the first try. As a rule of thumb, grow the instances exponentially; if you need to run a computation over an eight-node cluster, start with one node and an eighth of the entire dataset, then two nodes with a fourth, then four nodes with half of the dataset, and then, finally, eight nodes and the entire dataset. As you become more experienced, you’ll develop a good sense of how to troubleshoot issues, and of the size of the required cluster, and you’ll be able to skip intermediate steps, but for starters, this is a good practice to follow.
You can also use a cloud provider to acquire bare computing resources and then install the on-premises distributions presented in the previous section yourself; for instance, you can run the Cloudera distribution on Amazon Elastic Compute Cloud (Amazon EC2). This model would avoid procuring colocated hardware, but it still allows you to closely manage and customize your cluster. This book presents an overview of only the fully managed Spark services available by cloud providers; however, you can usually find with ease instructions online on how to install on-premises distributions in the cloud.
Some of the major providers of cloud computing infrastructure are Amazon, Databricks, Google, IBM, and Microsoft and Qubole. The subsections that follow briefly introduce each one.
6.3.1 Amazon
Amazon provides cloud services through AWS; more specifically, it provides an on-demand Spark cluster through Amazon EMR.
Detailed instructions on using R with Amazon EMR were published under Amazon’s Big Data blog in a post called “Running sparklyr on Amazon EMR”. This post introduced the launch of sparklyr and instructions to configure Amazon EMR clusters with sparklyr. For instance, it suggests you can use the Amazon Command Line Interface to launch a cluster with three nodes, as follows:
aws emr create-cluster --applications Name=Hadoop Name=Spark Name=Hive \
--release-label emr-5.8.0 --service-role EMR_DefaultRole --instance-groups \
InstanceGroupType=MASTER,InstanceCount=1,InstanceType=m3.2xlarge \
InstanceGroupType=CORE,InstanceCount=2,InstanceType=m3.2xlarge \
--bootstrap-action Path=s3://aws-bigdata-blog/artifacts/aws-blog-emr-\
rstudio-sparklyr/rstudio_sparklyr_emr5.sh,Args=["--user-pw", "<password>", \
"--rstudio", "--arrow"] --ec2-attributes InstanceProfile=EMR_EC2_DefaultRoleYou can then see the cluster launching and then eventually running under the AWS portal, as illustrated in Figure 6.8.
You then can navigate to the Master Public DNS and find RStudio under port 8787—for example, ec2-12-34-567-890.us-west-1.compute.amazonaws.com:8787—and then log in with user hadoop and password password.
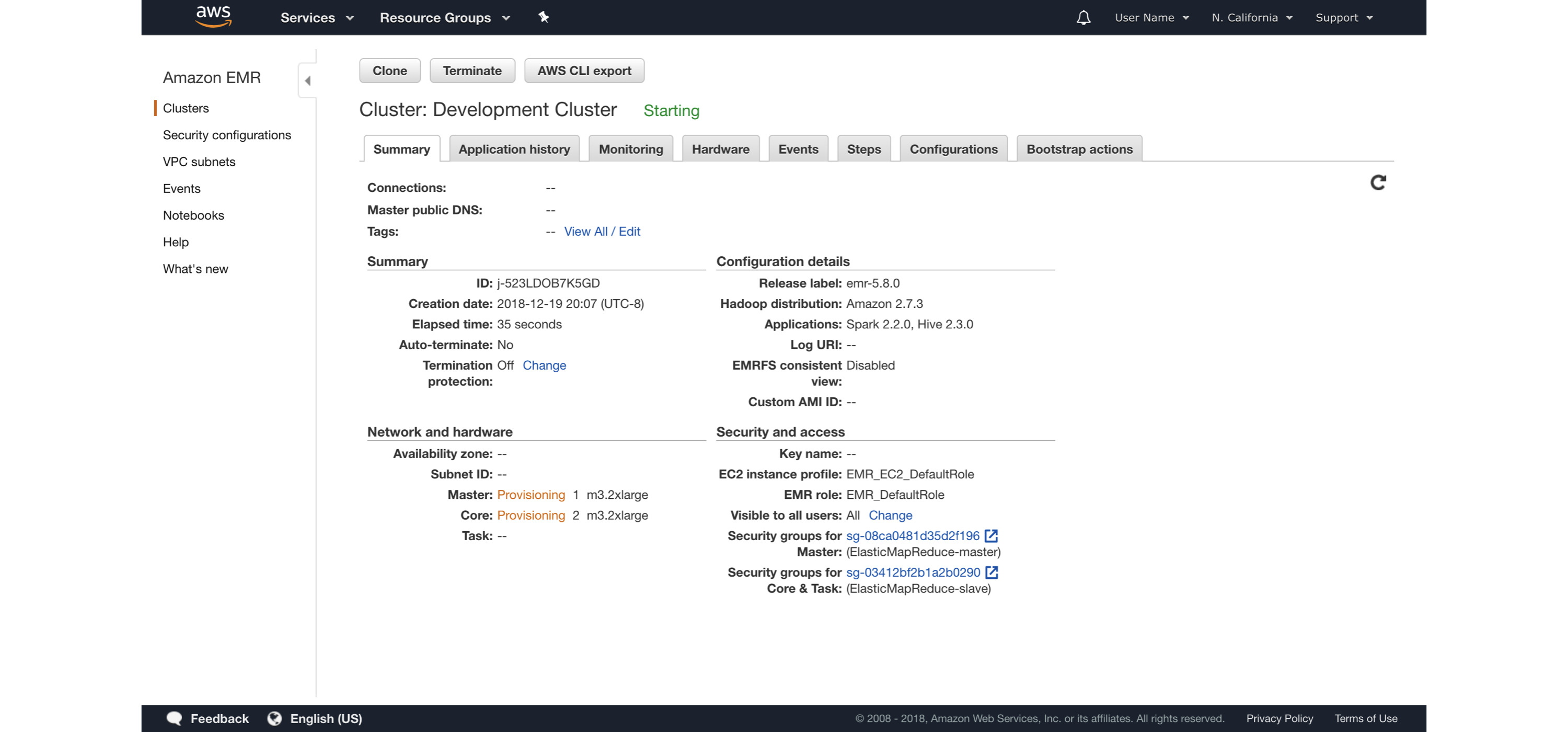
FIGURE 6.8: Launching an Amazon EMR cluster
It is also possible to launch the Amazon EMR cluster using the web interface; the same introductory post contains additional details and walkthroughs specifically designed for Amazon EMR.
Remember to turn off your cluster to avoid unnecessary charges and use appropriate security restrictions when starting Amazon EMR clusters for sensitive data analysis.
Regarding cost, you can find the most up-to-date information at https://amzn.to/2YRGb5r[Amazon EMR Pricing]. Table 6.2 presents some of the instance types available in the us-west-1 region (as of this writing); this is meant to provide a glimpse of the resources and costs associated with cloud processing. Notice that the “EMR price is in addition to the Amazon EC2 price (the price for the underlying servers)”.
| Instance | CPUs | Memory | Storage | EC2.Cost | EMR.Cost |
|---|---|---|---|---|---|
| c1.medium | 2 | 1.7GB | 350GB | $0.148 USD/hr | $0.030 USD/hr |
| m3.2xlarge | 8 | 30GB | 160GB | $0.616 USD/hr | $0.140 USD/hr |
| i2.8xlarge | 32 | 244GB | 6400GB | $7.502 USD/hr | $0.270 USD/hr |
Note: We are presenting only a subset of the available compute instances for Amazon and subsequent cloud providers as of 2019; however, note that hardware (CPU speed, hard drive speed, etc.) varies between vendors and locations; therefore, you can’t use these hardware tables as an accurate price comparison. Accurate comparison would require running your particular workloads and considering other aspects beyond compute instance cost.
6.3.2 Databricks
Databricks is a company founded by the creators of Apache Spark, whose aim is to help clients with cloud-based big data processing using Spark. Databricks grew out of the AMPLab project at the University of California, Berkeley.
Databricks provides enterprise-level cluster computing plans as well as a free/community tier to explore functionality and become familiar with their environment.
After a cluster is launched, you can use R and sparklyr from Databricks notebooks following the steps provided in Chapter 2 or by installing RStudio on Databricks. Figure 6.9 shows a Databricks notebook using Spark through sparkylyr.
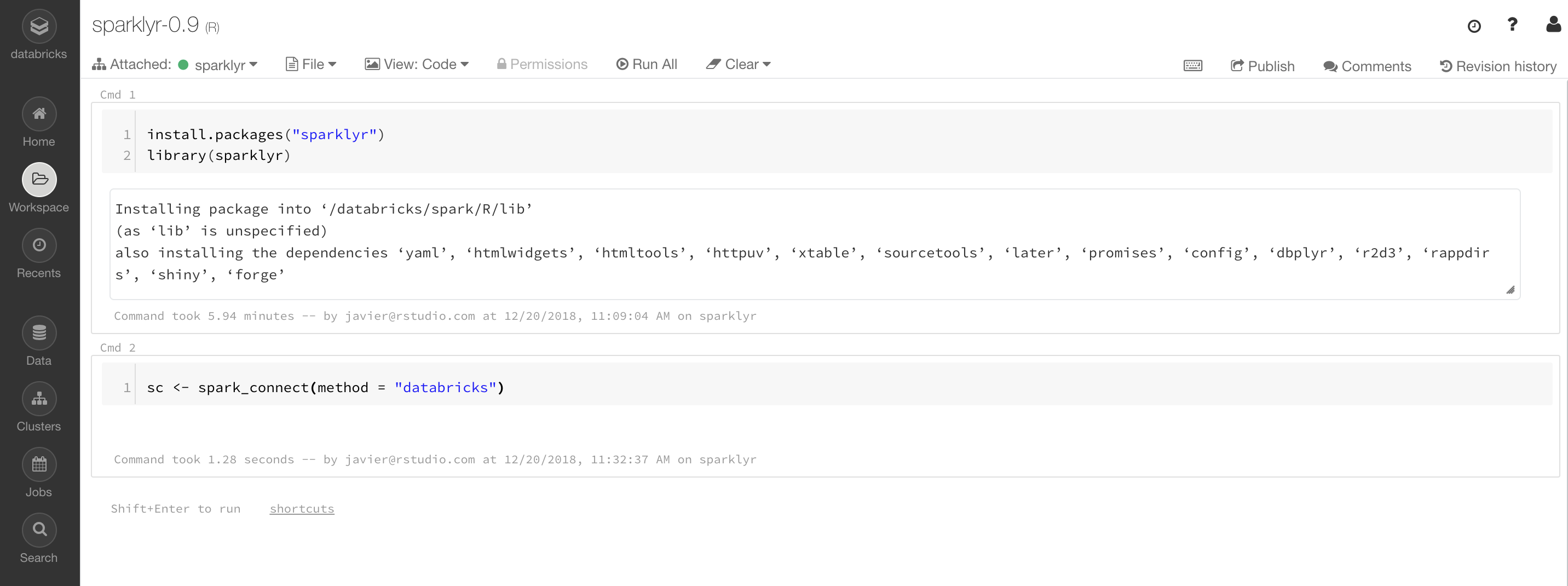
FIGURE 6.9: Databricks community notebook running sparklyr
Additional resources are available under the Databricks Engineering Blog post “Using sparklyr in Databricks” and the Databricks documentation for sparklyr.
You can find the latest pricing information at databricks.com/product/pricing. Table 6.3 lists the available plans as of this writing.
| Plan | Basic | Data.Engineering | Data.Analytics |
|---|---|---|---|
| AWS Standard | $0.07 USD/DBU | $0.20 USD/DBU | $0.40 USD/DBU |
| Azure Standard | $0.20 USD/DBU | $0.40 USD/DBU | |
| Azure Premium | $0.35 USD/DBU | $0.55 USD/DBU |
Notice that pricing is based on cost of DBU per hour. From Databricks, “a Databricks Unit (DBU) is a unit of Apache Spark processing capability per hour. For a varied set of instances, DBUs are a more transparent way to view usage instead of the node-hour”.
6.3.3 Google
Google provides Google Cloud Dataproc as a cloud-based managed Spark and Hadoop service offered on Google Cloud Platform (GCP). Dataproc utilizes many GCP technologies, such as Google Compute Engine and Google Cloud Storage, to offer fully managed clusters running popular data processing frameworks such as Apache Hadoop and Apache Spark.
You can easily create a cluster from the Google Cloud console or the Google Cloud command-line interface (CLI) as illustrated in Figure 6.10.
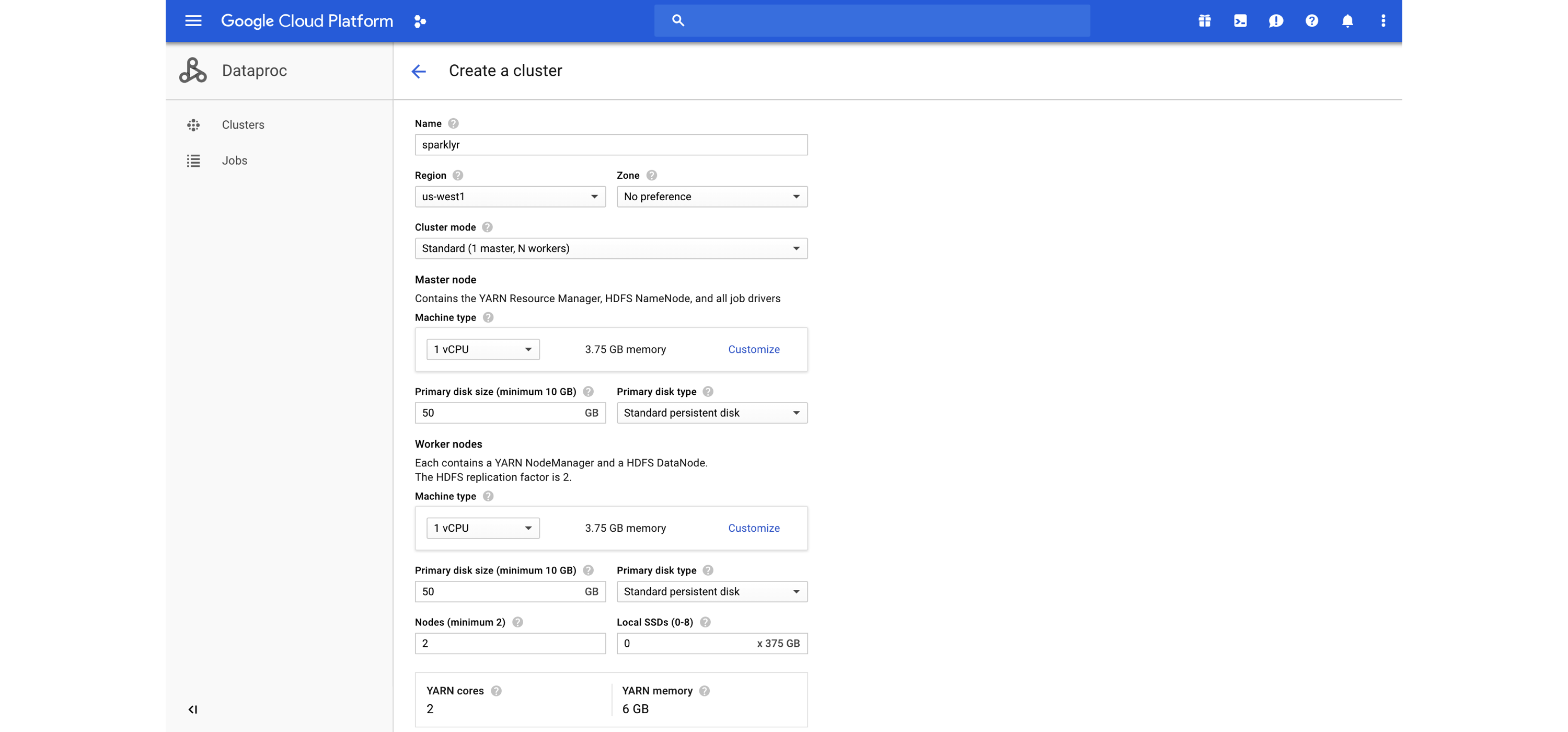
FIGURE 6.10: Launching a Dataproc cluster
After you’ve created your cluster, ports can be forwarded to allow you to access this cluster from your machine—for instance, by launching Chrome to make use of this proxy and securely connect to the Dataproc cluster. Configuring this connection looks as follows:
gcloud compute ssh sparklyr-m --project=<project> --zone=<region> -- -D 1080 \
-N "<path to chrome>" --proxy-server="socks5://localhost:1080" \
--user-data-dir="/tmp/sparklyr-m" http://sparklyr-m:8088There are various tutorials available (cloud.google.com/dataproc/docs/tutorials), including a comprehensive tutorial to configure RStudio and sparklyr.
You can find the latest pricing information at cloud.google.com/dataproc/pricing. In Table 6.4 notice that the cost is split between compute engine and a dataproc premium.
| Instance | CPUs | Memory | Compute.Engine | Dataproc.Premium |
|---|---|---|---|---|
| n1-standard-1 | 1 | 3.75GB | $0.0475 USD/hr | $0.010 USD/hr |
| n1-standard-8 | 8 | 30GB | $0.3800 USD/hr | $0.080 USD/hr |
| n1-standard-64 | 64 | 244GB | $3.0400 USD/hr | $0.640 USD/hr |
6.3.4 IBM
IBM cloud computing is a set of cloud computing services for business. IBM cloud includes Infrastructure as a Service (IaaS), Software as a Service (SaaS), and Platform as a Service (PaaS) offered through public, private, and hybrid cloud delivery models, in addition to the components that make up those clouds.
From within IBM Cloud, open Watson Studio and create a Data Science project, add a Spark cluster under the project settings, and then, on the Launch IDE menu, start RStudio. Please note that, as of this writing, the provided version of sparklyr was not the latest version available in CRAN, since sparklyr was modified to run under the IBM Cloud. In any case, follow IBM’s documentation as an authoritative reference to run R and Spark on the IBM Cloud and particularly on how to upgrade sparklyr appropriately. Figure 6.11 captures IBM’s Cloud portal launching a Spark cluster.
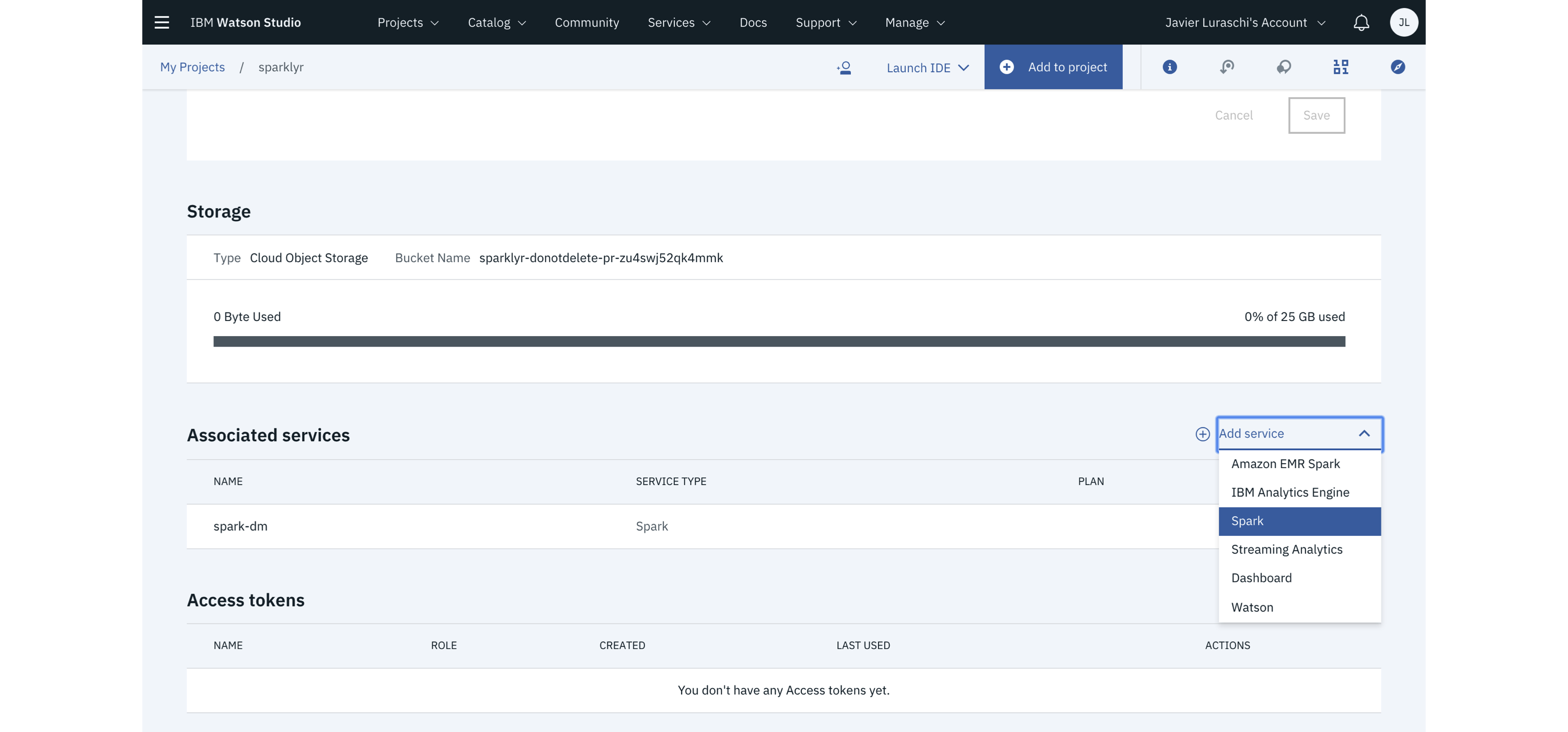
FIGURE 6.11: IBM Watson Studio launching Spark with R support
The most up-to-date pricing information is available at ibm.com/cloud/pricing. In Table 6.5, compute cost was normalized using 31 days from the per-month costs.
| Instance | CPUs | Memory | Storage | Cost |
|---|---|---|---|---|
| C1.1x1x25 | 1 | 1GB | 25GB | $0.033 USD/hr |
| C1.4x4x25 | 4 | 4GB | 25GB | $0.133 USD/hr |
| C1.32x32x25 | 32 | 25GB | 25GB | $0.962 USD/hr |
6.3.5 Microsoft
Microsoft Azure is a cloud computing service created by Microsoft for building, testing, deploying, and managing applications and services through a global network of Microsoft-managed datacenters. It provides SaaS, PaaS, and IaaS and supports many different programming languages, tools, and frameworks, including both Microsoft-specific and third-party software and systems.
From the Azure portal, the Azure HDInsight service provides support for on-demand Spark clusters. You can easily create HDInsight cluster with support for Spark and RStudio by selecting the ML Services cluster type. Note that the provided version of sparklyr might not be the latest version available in CRAN since the default package repository seems to be initialized using a Microsoft R Application Network (MRAN) snapshot, not directly from CRAN. Figure 6.12 shows the Azure portal launching a Spark cluster with support for R.
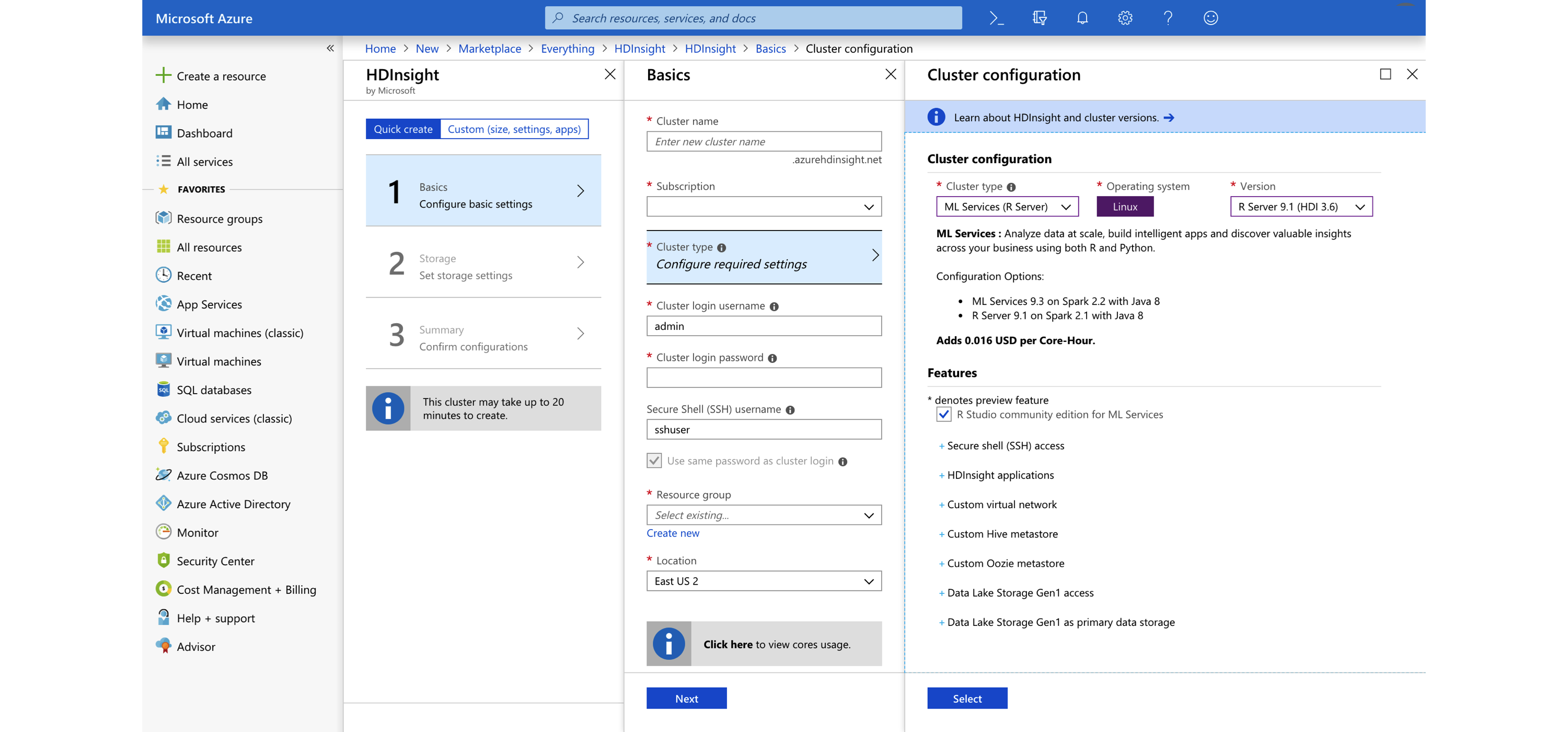
FIGURE 6.12: Creating an Azure HDInsight Spark cluster
Up-to-date pricing for HDInsight is available at azure.microsoft.com/en-us/pricing/details/hdinsight; Table 6.6 lists the pricing as of this writing.
| Instance | CPUs | Memory | Total.Cost |
|---|---|---|---|
| D1 v2 | 1 | 3.5 GB | $0.074/hour |
| D4 v2 | 8 | 28 GB | $0.59/hour |
| G5 | 64 | 448 GB | $9.298/hour |
6.3.6 Qubole
Qubole was founded in 2013 with a mission to close the data accessibility gap. Qubole delivers a self-service platform for big data analytics built on Amazon, Microsoft, Google, and Oracle Clouds. In Qubole, you can launch Spark clusters, which you can then use from Qubole notebooks or RStudio Server. Figure 6.13 shows a Qubole cluster initialized with RStudio and sparklyr.
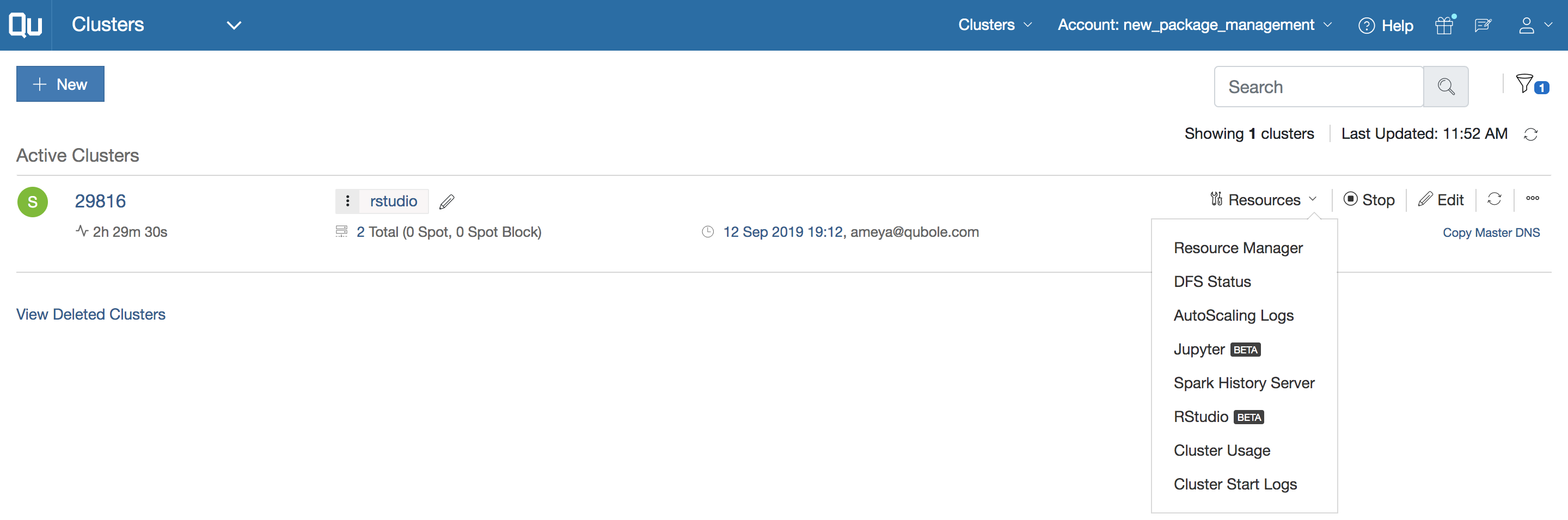
FIGURE 6.13: A Qubole cluster initialized with RStudio and sparklyr
You can find the latest pricing information at Qubole's pricing page. Table 6.7 lists the price for Qubole’s current plan, as of this writing. Notice that pricing is based on cost of QCU/hr, which stands for “Qubole Compute Unit per hour,” and the Enterprise Edition requires an annual contract.
| Test.Drive | Full.Featured.Trial | Enterprise.Edition |
|---|---|---|
| $0 USD | $0 USD | $0.14 USD/QCU |
6.4 Kubernetes
Kubernetes is an open source container orchestration system for automating deployment, scaling, and management of containerized applications that was originally designed by Google and is now maintained by the Cloud Native Computing Foundation (CNCF). Kubernetes was originally based on Docker, while, like Mesos, it’s also based on Linux Cgroups.
Kubernetes can execute many cluster applications and frameworks that you can highly customize by using container images with specific resources and libraries. This allows a single Kubernetes cluster to be used for many different purposes beyond data analysis, which in turn helps organizations manage their compute resources with ease. One trade-off from using custom images is that they add further configuration overhead but make Kubernetes clusters extremely flexible. Nevertheless, this flexibility has proven to be instrumental to easily administer cluster resources in many organizations and, as pointed out in Overview, Kubernetes is becoming a very popular cluster framework.
Kubernetes is supported across all major cloud providers. They all provide extensive documentation as to how to launch, manage, and tear down Kubernetes clusters; Figure 6.14 shows the GCP console while creating a Kubernetes cluster. You can deploy Spark over any Kubernetes cluster, and you can use R to connect, analyze, model, and more.
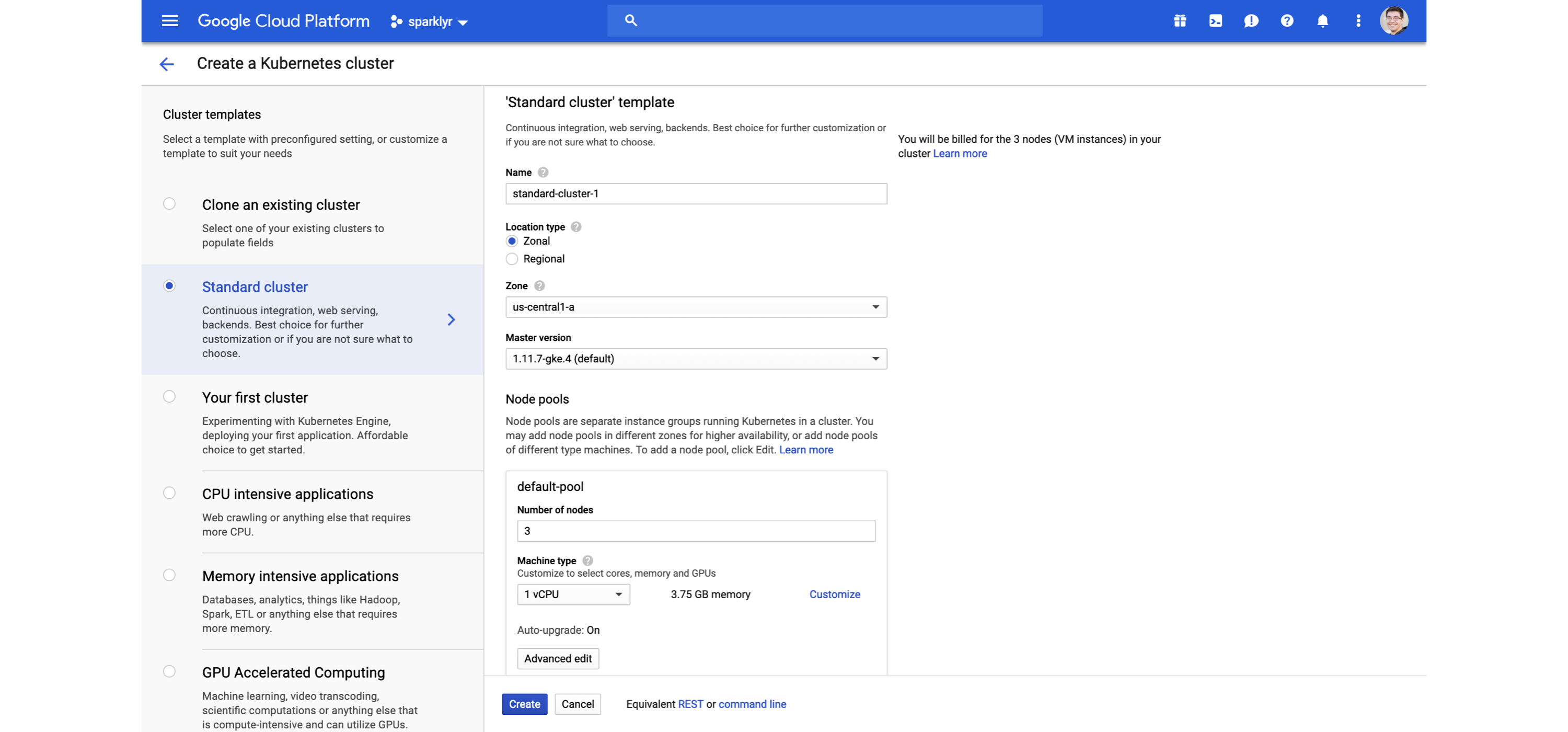
FIGURE 6.14: Creating a Kubernetes cluster for Spark and R using Google Cloud
You can learn more at kubernetes.io, and read the Running Spark on Kubernetes guide from spark.apache.org.
Strictly speaking, Kubernetes is a cluster technology, not a specific cluster architecture. However, Kubernetes represents a larger trend often referred to as a hybrid cloud. A hybrid cloud is a computing environment that makes use of on-premises and public cloud services with orchestration between the various platforms. It’s still too early to precisely categorize the leading technologies that will form a hybrid approach to cluster computing; although, as previously mentioned, Kubernetes is the leading one, many more are likely to form to complement or even replace existing technologies.
6.5 Tools
While using only R and Spark can be sufficient for some clusters, it is common to install complementary tools in your cluster to improve monitoring, SQL analysis, workflow coordination, and more, with applications like Ganglia, Hue, and Oozie, respectively. This section is not meant to cover all tools; rather, it mentions the ones that are commonly used.
6.5.1 RStudio
From reading Chapter 1, you are aware that RStudio is a well-known and free desktop development environment for R; therefore, it is likely that you are following the examples in this book using RStudio Desktop. However, you might not be aware that you can run RStudio as a web service within a Spark cluster. This version of RStudio is known as RStudio Server. You can see RStudio Server running in Figure 6.15. In the same way that the Spark UI runs in the cluster, you can install RStudio Server within the cluster. Then you can connect to RStudio Server and use RStudio in exactly the same way you use RStudio Desktop but with the ability to run code against the Spark cluster. As you can see in Figure 6.15, RStudio Server looks and feels just like RStudio Desktop, but adds support to run commands efficiently by being located within the cluster.
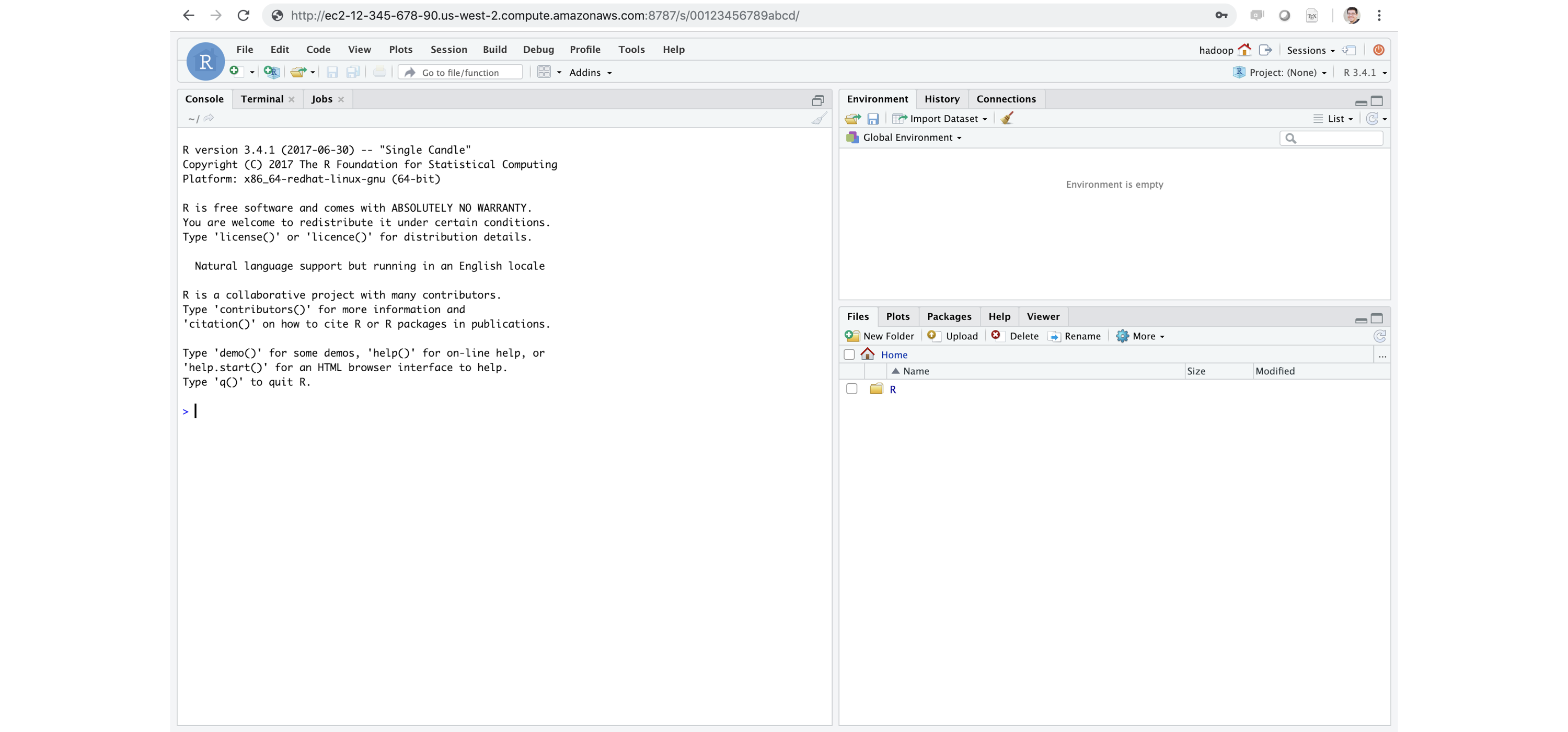
FIGURE 6.15: RStudio Server Pro running inside Apache Spark
If you’re familiar with R, Shiny Server is a very popular tool for building interactive web applications from R. We recommended that you install Shiny directly in your Spark cluster.
RStudio Server and Shiny Server are a free and open source; however, RStudio also provides professional products like RStudio Server, RStudio Server Pro, Shiny Server Pro, and RStudio Connect, which you can install within the cluster to support additional R workflows. While sparklyr does not require any additional tools, they provide significant productivity gains worth considering. You can learn more about them at rstudio.com/products/.
6.5.2 Jupyter
Project Jupyter exists to develop open source software, open standards, and services for interactive computing across dozens of programming languages. A Jupyter notebook provides support for various programming languages, including R. You can use sparklyr with Jupyter notebooks using the R Kernel. Figure 6.16 shows sparklyr running within a local Jupyter notebook.
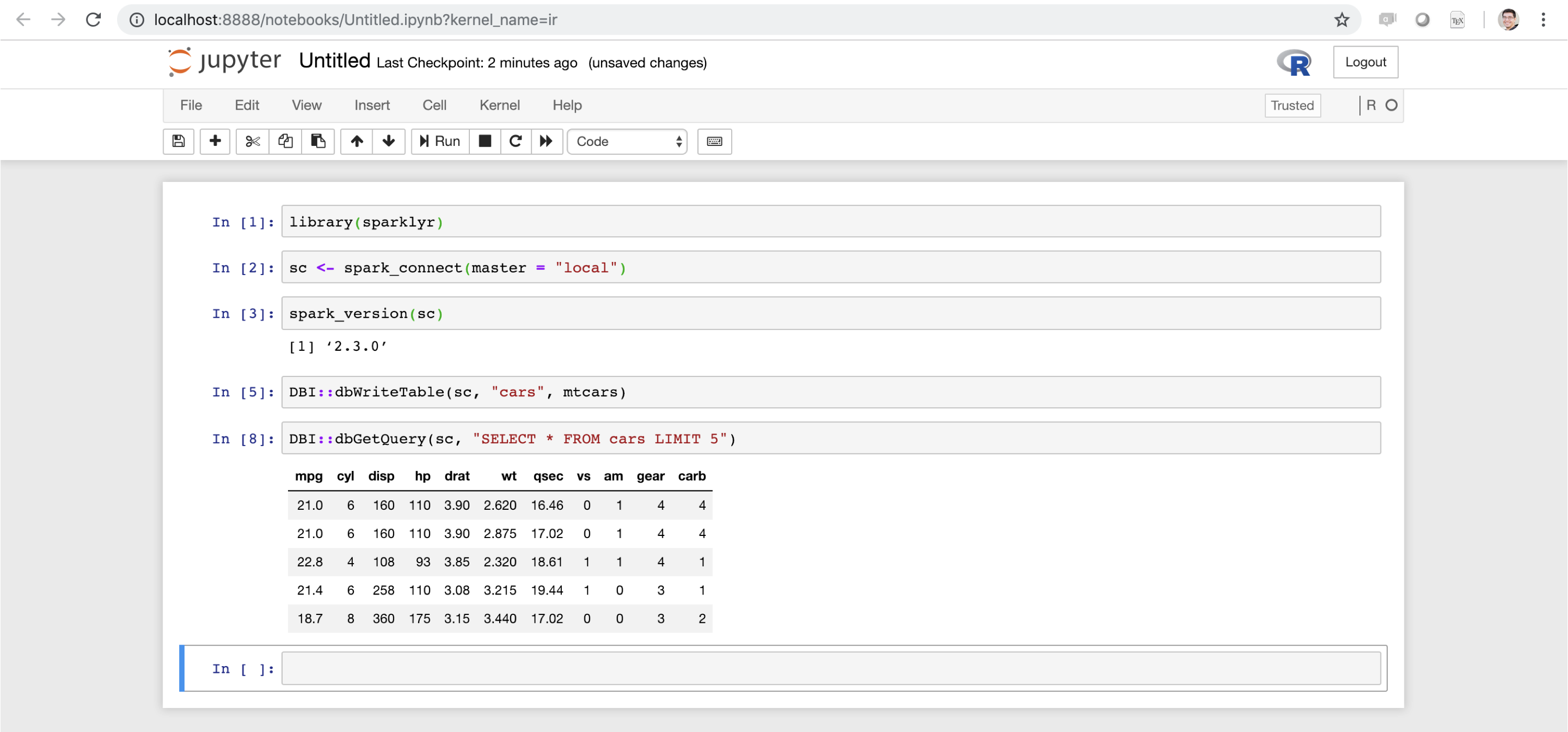
FIGURE 6.16: Jupyter notebook running sparklyr
6.5.3 Livy
Apache Livy is an incubation project in Apache providing support to use Spark clusters remotely through a web interface. It is ideal to connect directly into the Spark cluster; however, there are times where connecting directly to the cluster is not feasible. When facing those constraints, you can consider installing Livy in the cluster and secure it properly to enable remote use over web protocols. Be aware, though, that there is a significant performance overhead from using Livy in sparklyr.
To help test Livy locally, sparklyr provides support to list, install, start, and stop a local Livy instance by executing livy_available_versions():
## livy
## 1 0.2.0
## 2 0.3.0
## 3 0.4.0
## 4 0.5.0This lists the versions that you can install; we recommend installing the latest version and verifying it as follows:
# Install default Livy version
livy_install()
# List installed Livy services
livy_installed_versions()
# Start the Livy service
livy_service_start()You then can navigate to the local Livy session at http://localhost:8998. Chapter 7 will detail how to connect through Livy. After you’re connected, you can navigate to the Livy web application, as shown in Figure 6.17.
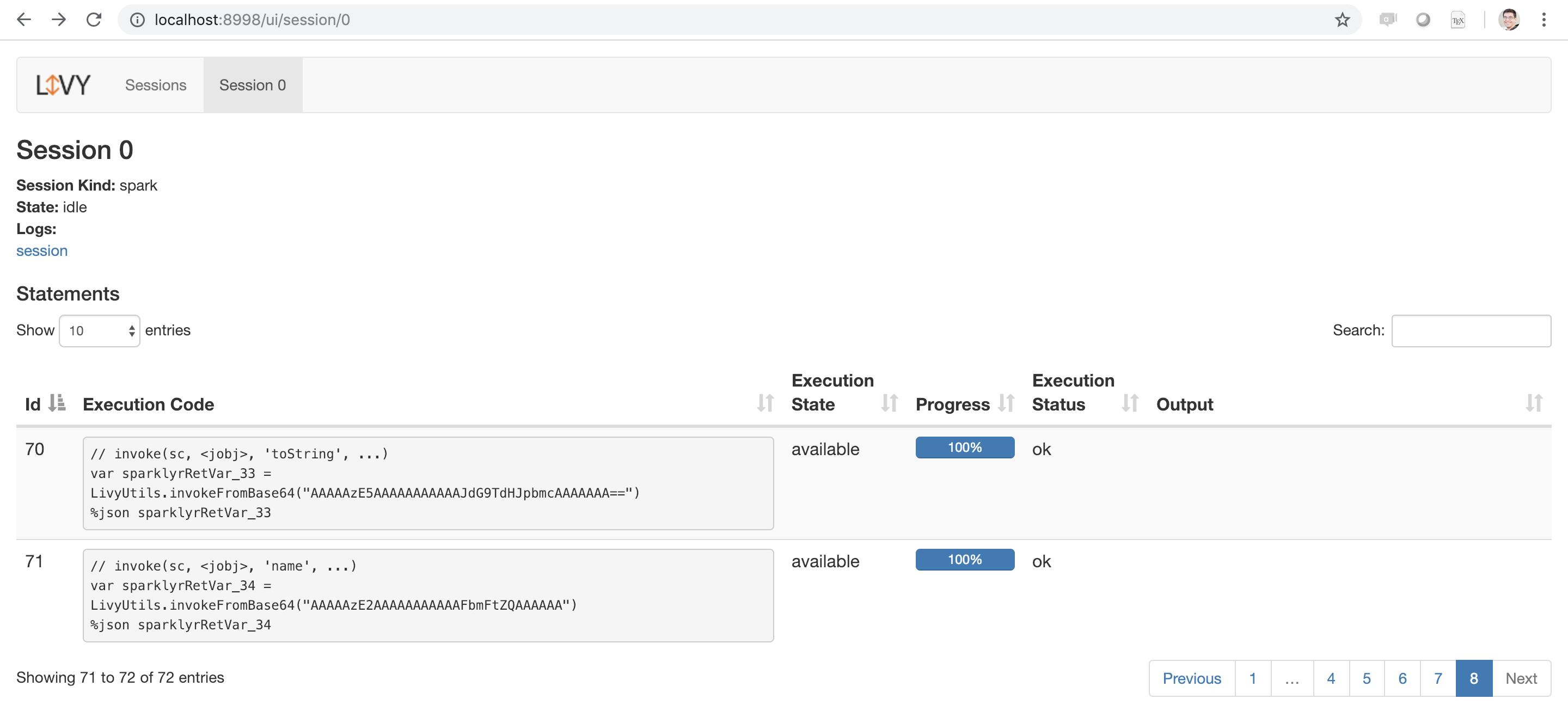
FIGURE 6.17: Apache Livy running as a local service
Make sure you also stop the Livy service when working with local Livy instances (for proper Livy services running in a cluster, you won’t have to):
6.6 Recap
This chapter explained the history and trade-offs of on-premises and cloud computing and presented Kubernetes as a promising framework to provide flexibility across on-premises or multiple cloud providers. It also introduced cluster managers (Spark Standalone, YARN, Mesos, and Kubernetes) as the software needed to run Spark as a cluster application. This chapter briefly mentioned on-premises cluster providers like Cloudera, Hortonworks, and MapR, as well as the major Spark cloud providers: Amazon, Databricks, IBM, Google, Microsoft, and Qubole.
While this chapter provided a solid foundation to understand current cluster computing trends, tools, and service providers useful to perform data science at scale, it did not provide a comprehensive framework to help you decide which cluster technologies to choose. Instead, use this chapter as an overview and a starting point to seek out additional resources to help you find the cluster stack that best fits your organization needs.
Chapter 7 will focus on understanding how to connect to existing clusters; therefore, it assumes a Spark cluster like those we presented in this chapter is already available to you.