Chapter 13 Contributing
Hold the door, hold the door.
— Hodor
In Chapter 12, we equipped you with the tools to tackle large-scale and real-time data processing in Spark using R. In this final chapter we focus less on learning and more on giving back to the Spark and R communities or colleagues in your professional career. It really takes an entire community to keep this going, so we are counting on you!
There are many ways to contribute, from helping community members and opening GitHub issues to providing new functionality for yourself, colleagues, or the R and Spark community. However, we’ll focus here on writing and sharing code that extends Spark, to help others use new functionality you can provide as an author of Spark extensions using R. Specifically, you’ll learn what an extension is, the different types of extensions you can build, what building tools are available, and when and how to build an extension from scratch.
You will also learn how to make use of the hundreds of extensions available in Spark and the millions of components available in Java that can easily be used in R. We’ll also cover how to create code natively in Scala that makes use of Spark. As you might know, R is a great language for interfacing with other languages, such as C++, SQL, Python, and many others. It’s no surprise, then, that working with Scala from R will follow similar practices that make R ideal for providing easy-to-use interfaces that make data processing productive and that are loved by many of us.
13.1 Overview
When you think about giving back to your larger coding community, the most important question you can ask about any piece of code you write is: would this code be useful to someone else?
Let’s start by considering one of the first and simplest lines of code presented in this book. This code was used to load a simple CSV file:
Code this basic is probably not useful to someone else. However, you could tailor that same example to something that generates more interest, perhaps the following:
This code is quite similar to the first. But if you work with others who are working with this dataset, the answer to the question about usefulness would be yes—this would very likely be useful to someone else!
This is surprising since it means that not all useful code needs to be advanced or complicated. However, for it to be useful to others, it does need to be packaged, presented, and shared in a format that is easy to consume.
A first attempt would be to save this into a teamdata.R file and write a function wrapping it:
This is an improvement, but it would require users to manually share this file again and again. Fortunately, this problem is easily solved in R, through R packages.
An R package contains R code in a format that is installable using the function install.packages(). One example is sparklyr. There are many other R packages available; you can also create your own. For those of you new to creating them, we encourage you to read Hadley Wickham’s book, R Packages (O’Reilly). Creating an R package allows you to easily share your functions with others by sharing the package file in your organization.
Once you create a package, there are many ways of sharing it with colleagues or the world. For instance, for packages meant to be private, consider using Drat or products like RStudio Package Manager. R packages meant for public consumption are made available to the R community in CRAN (the Comprehensive R Archive Network).
These repositories of R packages allow users to install packages through install.packages("teamdata") without having to worry where to download the package from. It also allows other packages to reuse your package.
In addition to using R packages like sparklyr, dplyr, broom, and others to create new R packages that extend Spark, you can also use all the functionality available in the Spark API or Spark Extensions or write custom Scala code.
For instance, suppose that there is a new file format similar to a CSV but not quite the same. We might want to write a function named spark_read_file() that would take a path to this new file type and read it in Spark. One approach would be to use dplyr to process each line of text or any other R library using spark_apply(). Another would be to use the Spark API to access methods provided by Spark. A third approach would be to check whether someone in the Spark community has already provided a Spark extension that supports this new file format. Last but not least, you could write your own custom Scala code that makes use of any Java library, including Spark and its extensions. This is shown in Figure 13.1.
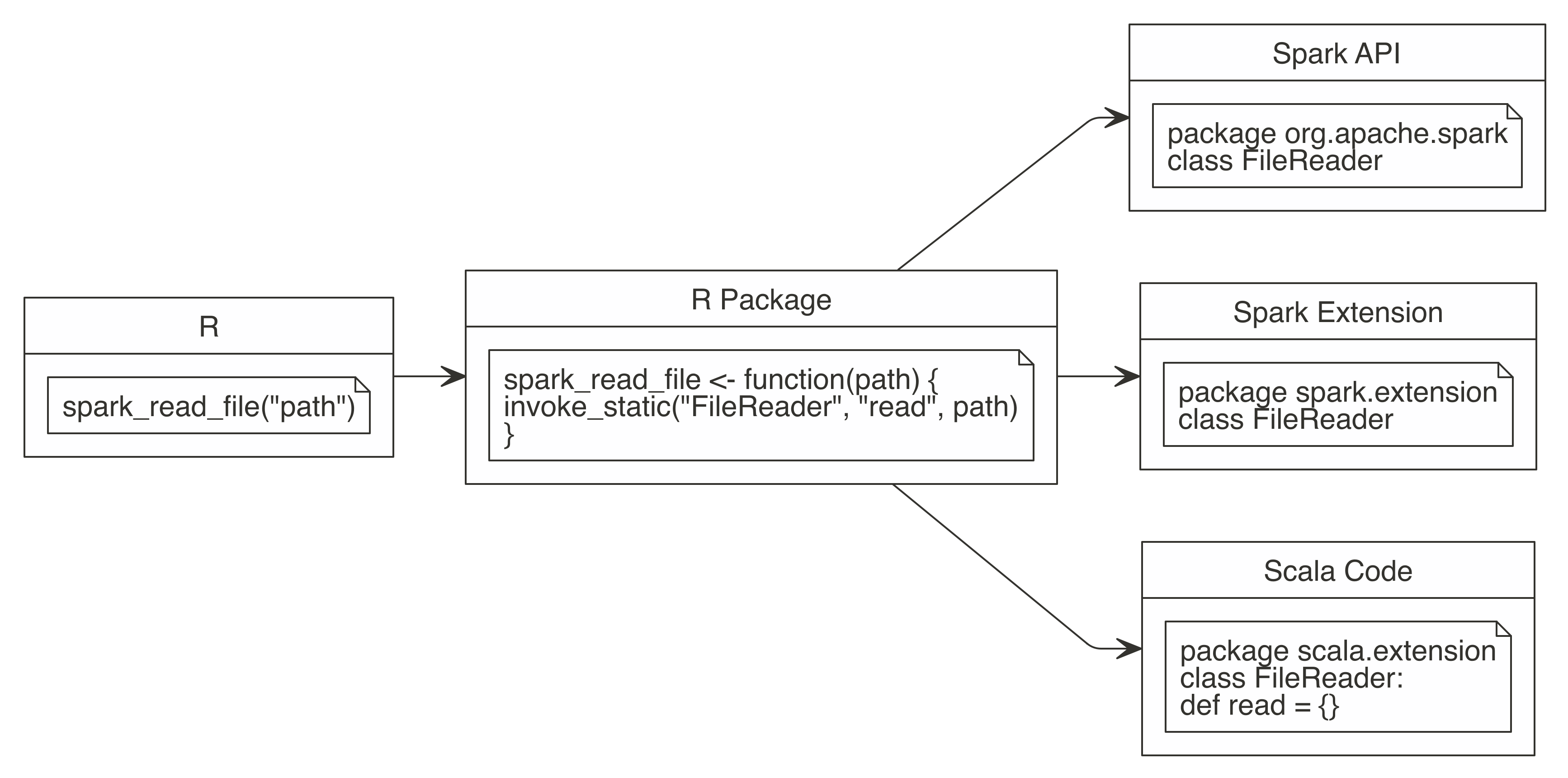
FIGURE 13.1: Extending Spark using the Spark API or Spark extensions, or writing Scala code
We will focus first on extending Spark using the Spark API, since the techniques required to call the Spark API are also applicable while calling Spark extensions or custom Scala code.
13.2 Spark API
Before we introduce the Spark API, let’s consider a simple and well-known problem. Suppose we want to count the number of lines in a distributed and potentially large text file—say, cars.csv, which we initialize as follows:
library(sparklyr)
library(dplyr)
sc <- spark_connect(master = "local", version = "2.3")
cars <- copy_to(sc, mtcars)
spark_write_csv(cars, "cars.csv", mode = "overwrite")Now, to count how many lines are available in this file, we can run the following:
# Source: spark<?> [?? x 1]
n
<dbl>
1 33Easy enough: we used spark_read_text() to read the entire text file, followed by counting lines using dplyr’s count(). Now, suppose that neither spark_read_text(), nor dplyr, nor any other Spark functionality, is available to you. How would you ask Spark to count the number of rows in cars.csv?
If you do this in Scala, you find in the Spark documentation that by using the Spark API you can count lines in a file as follows:
So, to use the functionality available in the Spark API from R, like spark.read.textFile, you can use invoke(), invoke_static(), or invoke_new(). (As their names suggest, the first invokes a method from an object, the second invokes a method from a static object, and the third creates a new object.) We then use these functions to call Spark’s API and execute code similar to the one provided in Scala:
[1] 33While the invoke() function was originally designed to call Spark code, it can also call any code available in Java. For instance, we can create a Java BigInteger with the following code:
<jobj[225]>
java.math.BigInteger
1000000000As you can see, the object created is not an R object but rather a proper Java object. In R, this Java object is represented by the spark_jobj. These objects are meant to be used with the invoke() functions or spark_dataframe() and spark_connection(). spark_dataframe() transforms a spark_jobj into a Spark DataFrame when possible, whereas spark_connect() retrieves the original Spark connection object, which can be useful to avoid passing the sc object across functions.
While calling the Spark API can be useful in some cases, most of the functionality available in Spark is already supported in sparklyr. Therefore, a more interesting way to extend Spark is by using one of its many existing extensions.
13.3 Spark Extensions
Before we get started with this section, consider navigating to spark-packages.org, a site that tracks Spark extensions provided by the Spark community. Using the same techniques presented in the previous section, you can use these extensions from R.
For instance, there is Apache Solr, a system designed to perform full-text searches over large datasets, something that Apache Spark currently does not support natively. Also, as of this writing, there is no extension for R to support Solr. So, let’s try to solve this by using a Spark extension.
First, if you search “spark-packages.org” to find a Solr extension, you should be able to locate spark-solr. The “How to” extension mentions that the com.lucidworks.spark:spark-solr:2.0.1 should be loaded. We can accomplish this in R using the sparklyr.shell.packages configuration option:
config <- spark_config()
config["sparklyr.shell.packages"] <- "com.lucidworks.spark:spark-solr:3.6.3"
config["sparklyr.shell.repositories"] <-
"http://repo.spring.io/plugins-release/,http://central.maven.org/maven2/"
sc <- spark_connect(master = "local", config = config, version = "2.3")While specifying the sparklyr.shell.packages parameter is usually enough, for this particular extension, dependencies failed to download from the Spark packages repository. You would need to manually find the failed dependencies in the Maven repo and add further repositories under the sparklyr.shell.repositories parameter.
Note: When you use an extension, Spark connects to the Maven package repository to retrieve it. This can take significant time depending on the extension and your download speeds. In this case, consider using the sparklyr.connect.timeout configuration parameter to allow Spark to download the required files.
From the spark-solr documentation, you would find that this extension can be used with the following Scala code:
val options = Map(
"collection" -> "{solr_collection_name}",
"zkhost" -> "{zk_connect_string}"
)
val df = spark.read.format("solr")
.options(options)
.load()We can translate this to R code:
spark_session(sc) %>%
invoke("read") %>%
invoke("format", "solr") %>%
invoke("option", "collection", "<collection>") %>%
invoke("option", "zkhost", "<host>") %>%
invoke("load")This code will fail, however, since it would require a valid Solr instance and configuring Solr goes beyond the scope of this book. But this example provides insights as to how you can create Spark extensions. It’s also worth mentioning that you can use spark_read_source() to read from generic sources to avoid writing custom invoke() code.
As pointed out in Overview, consider sharing code with others using R packages. While you could require users of your package to specify sparklyr.shell.packages, you can avoid this by registering dependencies in your R package. Dependencies are declared under a spark_dependencies() function; thus, for the example in this section:
spark_dependencies <- function(spark_version, scala_version, ...) {
spark_dependency(
packages = "com.lucidworks.spark:spark-solr:3.6.3",
repositories = c(
"http://repo.spring.io/plugins-release/",
"http://central.maven.org/maven2/")
)
}
.onLoad <- function(libname, pkgname) {
sparklyr::register_extension(pkgname)
}The onLoad function is automatically called by R when your library loads. It should call register_extension(), which will then call back spark_dependencies(), to allow your extension to provide additional dependencies. This example supports Spark 2.4, but you should also support mapping Spark and Scala versions to the correct Spark extension version.
There are about 450 Spark extensions you can use; in addition, you can also use any Java library from a Maven repository, where Maven Central has over 3 million artifacts. While not all Maven Central libraries might be relevant to Spark, the combination of Spark extensions and Maven repositories certainly opens many interesting possibilities for you to consider!
However, for those cases where no Spark extension is available, the next section will teach you how to use custom Scala code from your own R package.
13.4 Scala Code
Scala code enables you to use any method in the Spark API, Spark extensions, or Java library. In addition, writing Scala code when running in Spark can provide performance improvements over R code using spark_apply(). In general, the structure of your R package will contain R code and Scala code; however, the Scala code will need to be compiled as JARs (Java ARchive files) and included in your package. Figure 13.2 shows this structure.
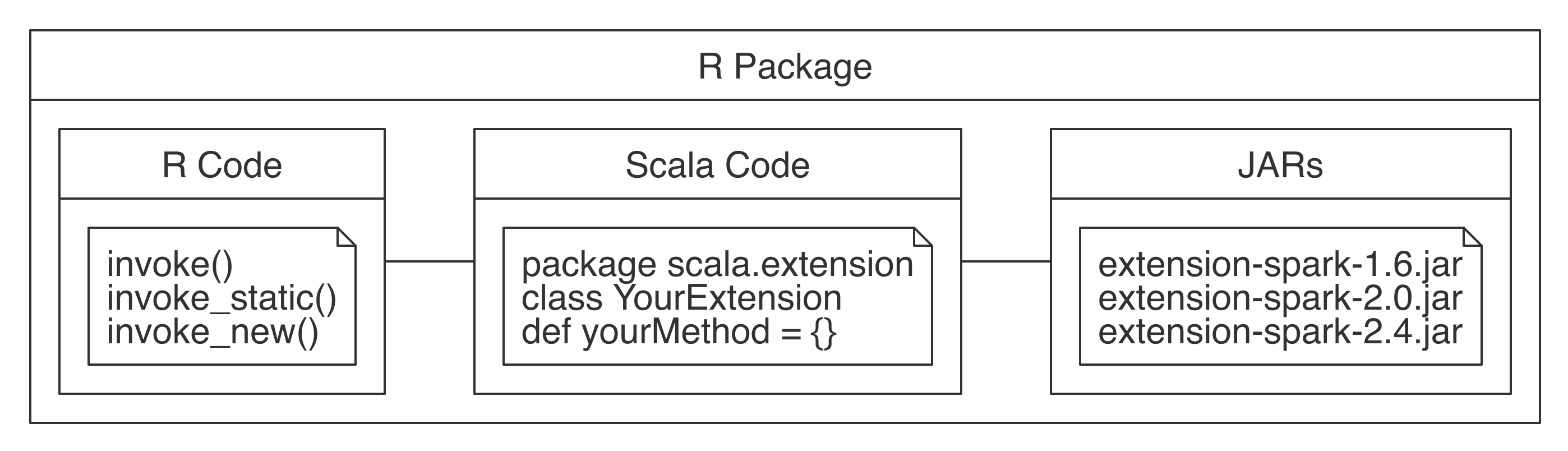
FIGURE 13.2: R package structure when using Scala code
As usual, the R code should be placed under a top-level R folder, Scala code under a java folder, and the compiled JARs under an inst/java folder. Though you are certainly welcome to manually compile the Scala code, you can use helper functions to download the required compiler and compile Scala code.
To compile Scala code, you’ll need to install the Java Development Kit 8 (JDK8, for short). Download the JDK from Oracle’s Java download page; this will require you to restart your R session.
You’ll also need a Scala compiler for Scala 2.11 and 2.12. The Scala compilers can be automatically downloaded and installed using download_scalac():
Next, you’ll need to compile your Scala sources using compile_package_jars(). By default, it uses spark_compilation_spec(), which compiles your sources for the following Spark versions:
[1] "1.5.2" "1.6.0" "2.0.0" "2.3.0" "2.4.0"You can also customize this specification by creating custom entries with spark_compilation_spec().
While you could create the project structure for the Scala code from scratch, you can also simply call spark_extension(path) to create an extension in the given path. This extension will be mostly empty but will contain the appropriate project structure to call the Scala code.
Since spark_extension() is registered as a custom project extension in RStudio, you can also create an R package that extends Spark using Scala code from the File menu; click New Project and then select “R Package using Spark” as shown in Figure 13.3.
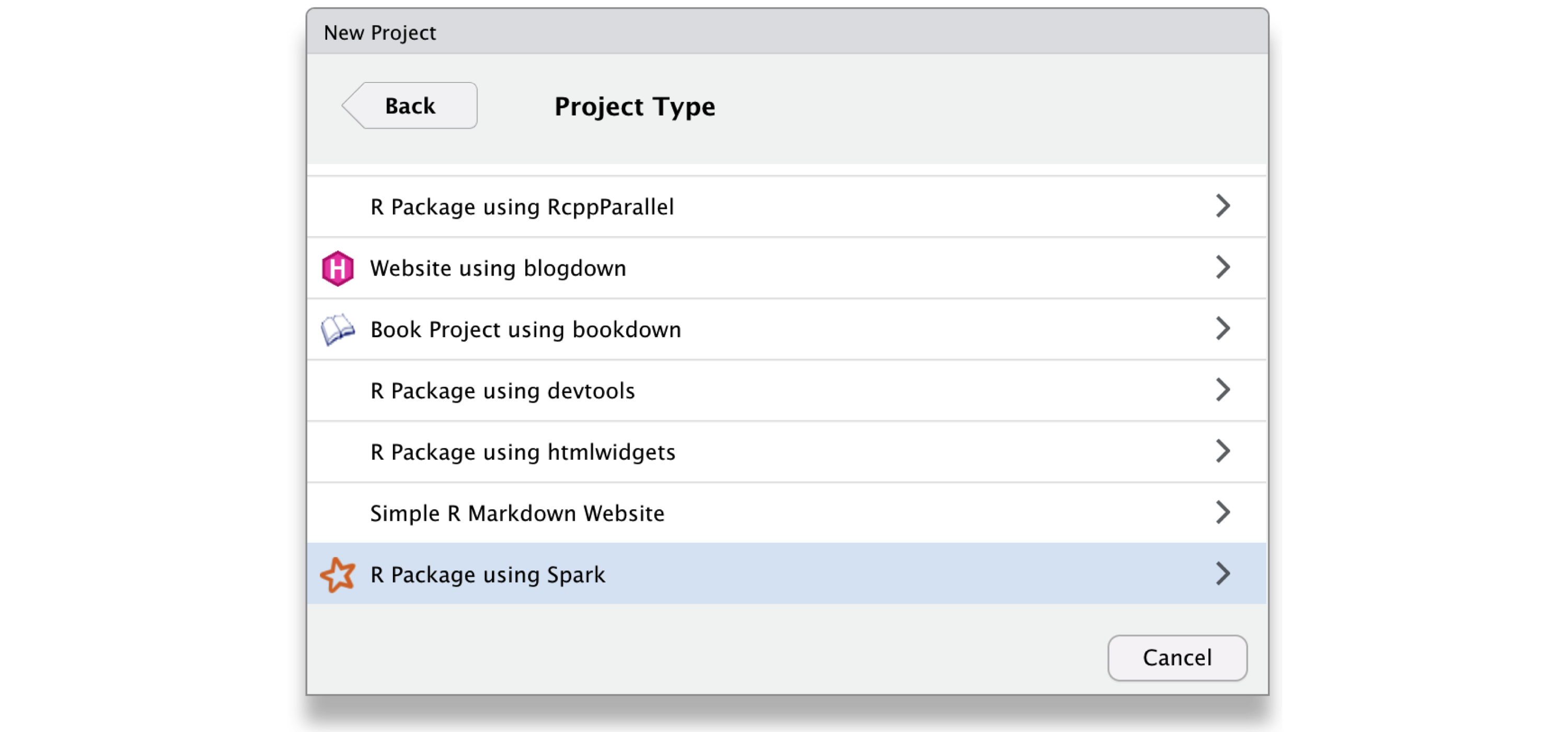
FIGURE 13.3: Creating a Scala extension package from RStudio
Once you are ready to compile your package JARs, you can simply run the following:
Since the JARs are compiled by default into the inst/ package path, when you are building the R package all the JARs will also be included within the package. This means that you can share or publish your R package, and it will be fully functional by R users. For advanced Spark users with most of their expertise in Scala, it’s compelling to consider writing libraries for R users and the R community in Scala and then easily packaging these into R packages that are easy to consume, use, and share among them.
If you are interested in developing a Spark extension with R and you get stuck along the way, consider joining the sparklyr Gitter channel, where many of us hang out to help this wonderful community to grow. We hope to hear from you soon!
13.5 Recap
This final chapter introduced you to a new set of tools to use to expand Spark functionality beyond what R and R packages currently support. This vast new space of libraries includes more than 450 Spark extensions and millions of Java artifacts you can use in Spark from R. Beyond these resources, you also learned how to build Java artifacts using Scala code that can be easily embedded and compiled from R.
This brings us back to this book’s purpose, presented early on; while we know you’ve learned how to perform large-scale computing using Spark in R, we’re also confident that you have acquired the knowledge required to help other community members through Spark extensions. We can’t wait to see your new creations, which will surely help grow the Spark and R communities at large.
To close, we hope the first chapters gave you an easy introduction to Spark and R. Following that, we presented analysis and modeling as foundations for using Spark, with the familiarity of R packages you already know and love. You moved on to learning how to perform large-scale computing in proper Spark clusters. The last third of this book focused on advanced topics: using extensions, distributing R code, processing real-time data, and, finally, giving back by using Spark extensions using R and Scala code.
We’ve tried to present the best possible content. However, if you know of any way to improve this book, please open a GitHub issue under the the-r-in-spark repo, and we’ll address your suggestions in upcoming revisions. We hope you enjoyed reading this book, and that you’ve learned as much as we have learned while writing it. We hope it was worthy of your time—it has been an honor having you as our reader.